-
텍스트마이닝_LSA란 무엇일까?Text Mining 2019. 11. 20. 21:49
LSA
LSA는 Latent Semantic Analysis의 준말이다. 한글로 그대로 번역하면 잠재, 의미, 분석이다. 잠재되어 있는 의미를 찾아내 분석한다는 말인 것 같다. 잠재되어 있는 의미를 찾기 위해 LSA는 SVD를 사용한다. SVD는 따로 설명하지 않으므로 SVD 포스트를 먼저 읽고 이 글을 읽는 것이 좋을 것이다. SVD를 하게 되면 Singular Values가 생긴다. 이 특이 값의 크기에 따라 원래 행렬의 정보량이 결정된다. 그래서 값이 큰 몇 개의 특이 값들을 가지고도 유용한 정보를 만들 수 있다.
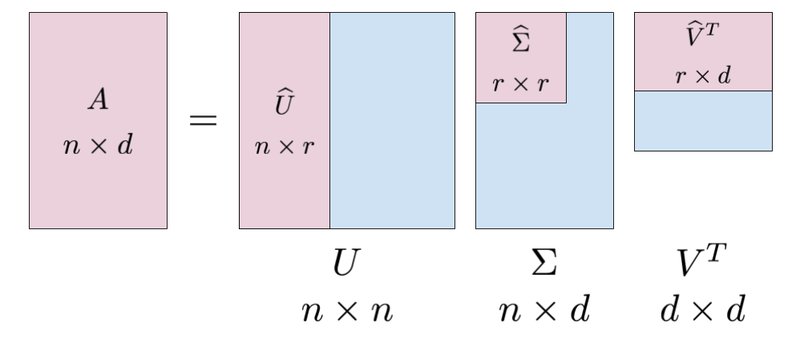
위 그림을 보면, A행렬은 n개의 행과 d개의 열이 있다. n은 단어들을 나타내고 d는 문서를 나타낸다. A행렬은 각 d_n문서에서 n개의 단어들의 빈도를 나타낸다고 볼 수 있다. A행렬이 차원 축소(truncated SVD)로 위 분홍색과 같이 분해된다면 아래와 같은 식이 성립될 수 있다.
$$U_r^T A_r = U_r^T U_r \Sigma_r V_r^T = I \Sigma_r V_r^T = \Sigma_r V_r^T = X_1$$ $$A_r V_r = U_r \Sigma_r V_r^T V_r = U_r \Sigma_r^T I = U_r V_r^T = X_2$$
U의 전치행렬을 곱했을 때 X1이 나오고, V를 곱했을 때 X2가 나온다.
X1은 행이 줄어서 도출되고, X2는 열이 줄어서 도출된다. 즉, A행렬이 축소되어 X1, X2로 나타낼 수 있기에 X1, X2는 잠재된 의미를 가지는 행렬이 되는 것이다. 몇개의 단어로 그 행렬을 나타낸다라는 것은 그 단어가 문서 안에서 중요한 의미를 갖는다는 것이다.
* 이 글은 이기창님의 ratsgo 블로그와 서울 과기대 이영훈 교수님의 수업을 참고했음을 밝힙니다.
'Text Mining' 카테고리의 다른 글
텍스트마이닝_LDA란 무엇일까? (0) 2019.12.18 텍스트마이닝_GloVe (0) 2019.12.18 텍스트마이닝_Word2Vec, Doc2Vec (0) 2019.12.17 텍스트마이닝_pLSA란 무엇일까? (0) 2019.11.21 텍스트마이닝_TF-IDF란 무엇일까? (0) 2019.11.20